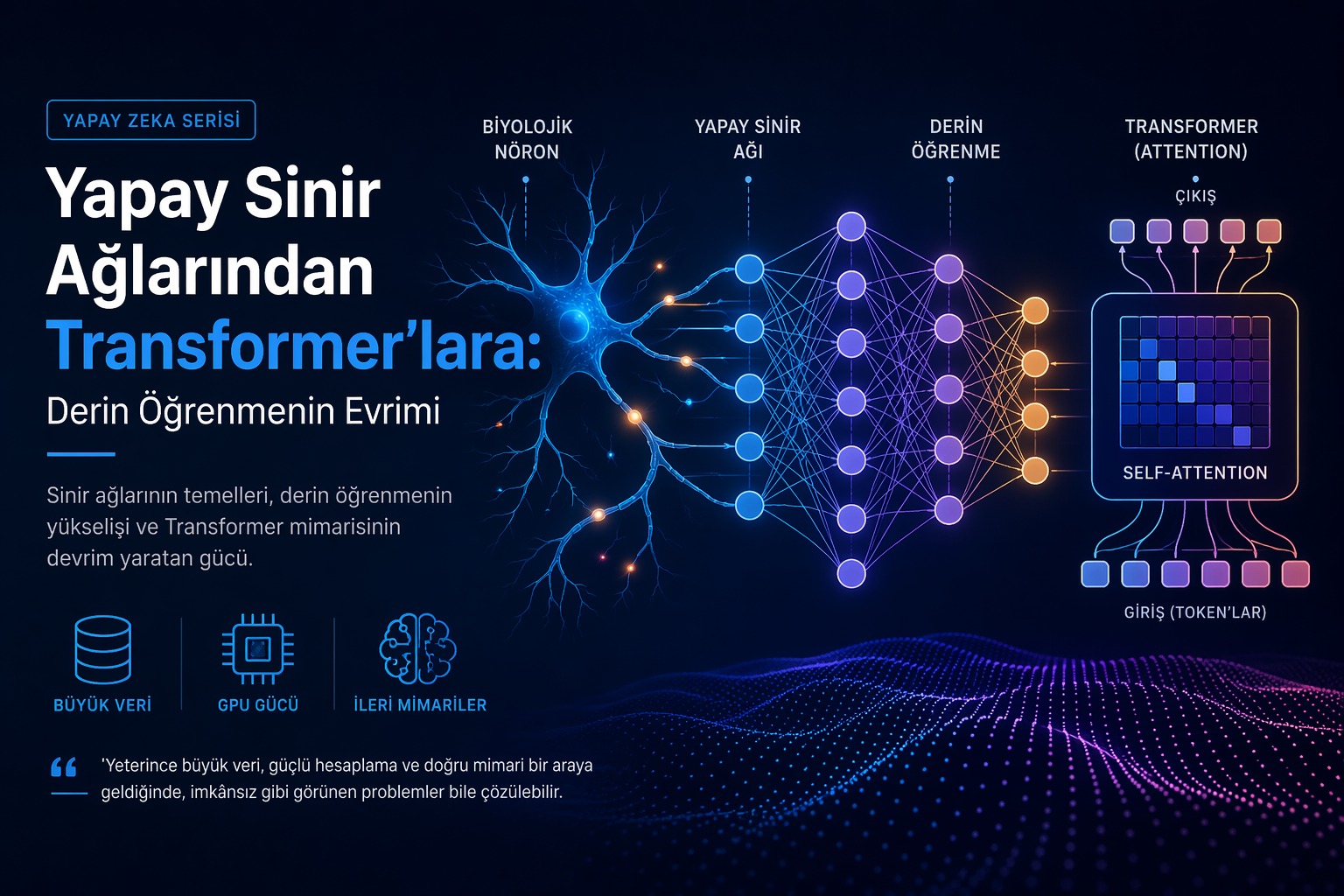
Makine Öğrenmesinden Pekiştirmeli Öğrenmeye: SVM ve Q-Learning
Makine öğrenmesi, verilerden anlam çıkararak karar verebilen sistemler geliştirmeyi amaçlayan bir alandır. Bu yazıda, iki önemli yaklaşımı sade bir şekilde ele alacağız: Destek Vektör Makineleri (SVM) ve Q-Learning ile Pekiştirmeli Öğrenme.
1. Destek Vektör Makineleri (SVM) Nedir?
SVM, özellikle sınıflandırma problemlerinde kullanılan güçlü bir makine öğrenmesi algoritmasıdır.
Temel Mantık
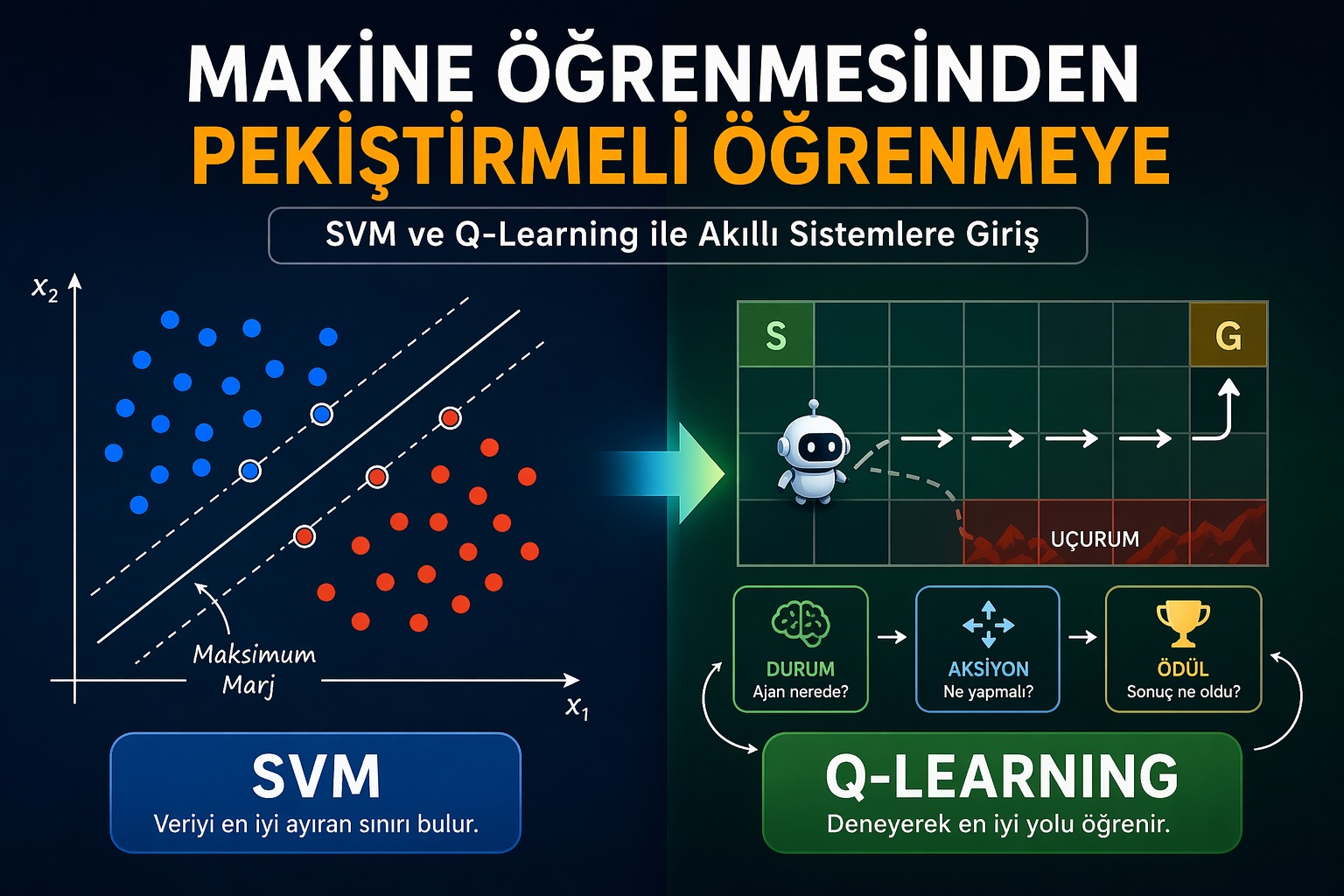
SVM’in amacı, verileri farklı sınıflara ayıran en iyi sınırı (hiperdüzlem) bulmaktır. Bu sınır:
- Sınıflar arasındaki mesafeyi maksimum yapar
- En kritik veri noktalarına (destek vektörleri) göre belirlenir
Basit Örnek
Bir e-posta uygulamasında:
- Spam ve normal e-postaları ayırmak istiyoruz
- SVM, bu iki grubu en iyi ayıran çizgiyi bulur
Kernel (Çekirdek) Kavramı
Bazı veriler doğrusal olarak ayrılamaz. İşte burada kernel devreye girer:
- Linear Kernel → Basit, doğrusal ayırma
- Polynomial Kernel → Daha karmaşık sınırlar
- RBF (Radial Basis Function) → En yaygın, esnek yapı
📌 Genellikle RBF kernel, karmaşık veri setlerinde daha iyi sonuç verir.
2. Pekiştirmeli Öğrenme (Reinforcement Learning) Nedir?
Pekiştirmeli öğrenme, bir ajanın (agent) deneme-yanılma yoluyla öğrenmesini sağlar.
Temel Bileşenler
- Ajan (Agent): Karar veren sistem
- Ortam (Environment): Ajanın içinde bulunduğu dünya
- Aksiyon (Action): Ajanın yaptığı hareket
- Ödül (Reward): Ajanın yaptığı hareketin sonucu
Amaç
Ajanın hedefi:
➡️ Toplam ödülü maksimize etmek
3. Q-Learning Nedir?
Q-Learning, pekiştirmeli öğrenmenin en temel algoritmalarından biridir.
Temel Fikir
Ajan, her durum ve aksiyon için bir değer öğrenir:
Q(state,action)Q(state, action)
Bu değer:
👉 “Bu durumda bu hareketi yaparsam ne kadar iyi olur?” sorusunun cevabıdır.
4. Q-Tablosu Nasıl Çalışır?
Q-Learning’de tüm bilgi bir tabloda tutulur:
| Durum | Sol | Sağ | Yukarı | Aşağı |
|---|---|---|---|---|
| S1 | 0.2 | 0.5 | 0.1 | 0.3 |
Ajan:
- Bulunduğu duruma bakar
- En yüksek Q değerine sahip aksiyonu seçer
5. Keşif vs Kullanım (Exploration vs Exploitation)
Ajan her zaman en iyi bildiğini yaparsa öğrenemez.
Bu yüzden iki strateji dengelenir:
- Exploration (Keşif): Rastgele hareketler → yeni şeyler öğrenir
- Exploitation (Kullanım): En iyi bilinen hareketi yapar
Bu denge genellikle epsilon-greedy yöntemiyle sağlanır:
- %90 en iyi hareket
- %10 rastgele hareket
6. Örnek: Uçurum Problemi (Cliff Walking)
Bu klasik problemde:
- Ajan başlangıç noktasından hedefe gitmeye çalışır
- Yanlış adım → uçurum → büyük ceza (örneğin -100)
- Her adım → küçük ceza (-1)
Öğrenme Süreci
Başta:
- Ajan rastgele dolaşır
- Çok fazla ceza alır
Zamanla:
- En kısa ve güvenli yolu öğrenir
- Daha az ceza alır
📈 Sonuç: Grafiklerde ödül zamanla iyileşir
7. SVM ve Q-Learning Arasındaki Fark
| Özellik | SVM | Q-Learning |
|---|---|---|
| Tür | Denetimli öğrenme | Pekiştirmeli öğrenme |
| Veri | Etiketli veri gerekir | Veri yok, deneyim var |
| Amaç | Sınıflandırma | Karar verme |
| Kullanım | Spam tespiti, görüntü sınıflandırma | Oyunlar, robotlar |
Sonuç
- SVM, verileri sınıflandırmak için güçlü ve matematiksel bir yöntemdir
- Q-Learning, bir ajanın deneyerek öğrenmesini sağlar
- İkisi farklı problemleri çözer ama makine öğrenmesinin temel taşlarıdır
Bu iki yaklaşımı anlamak, yapay zekâ dünyasına sağlam bir giriş yapmanı sağlar.
Kaynakça
- Christopher M. Bishop – Pattern Recognition and Machine Learning
- Richard S. Sutton & Andrew G. Barto – Reinforcement Learning: An Introduction
- Aurélien Géron – Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow
- Stanford CS229 Machine Learning Notes
- OpenAI Spinning Up – Reinforcement Learning Guide