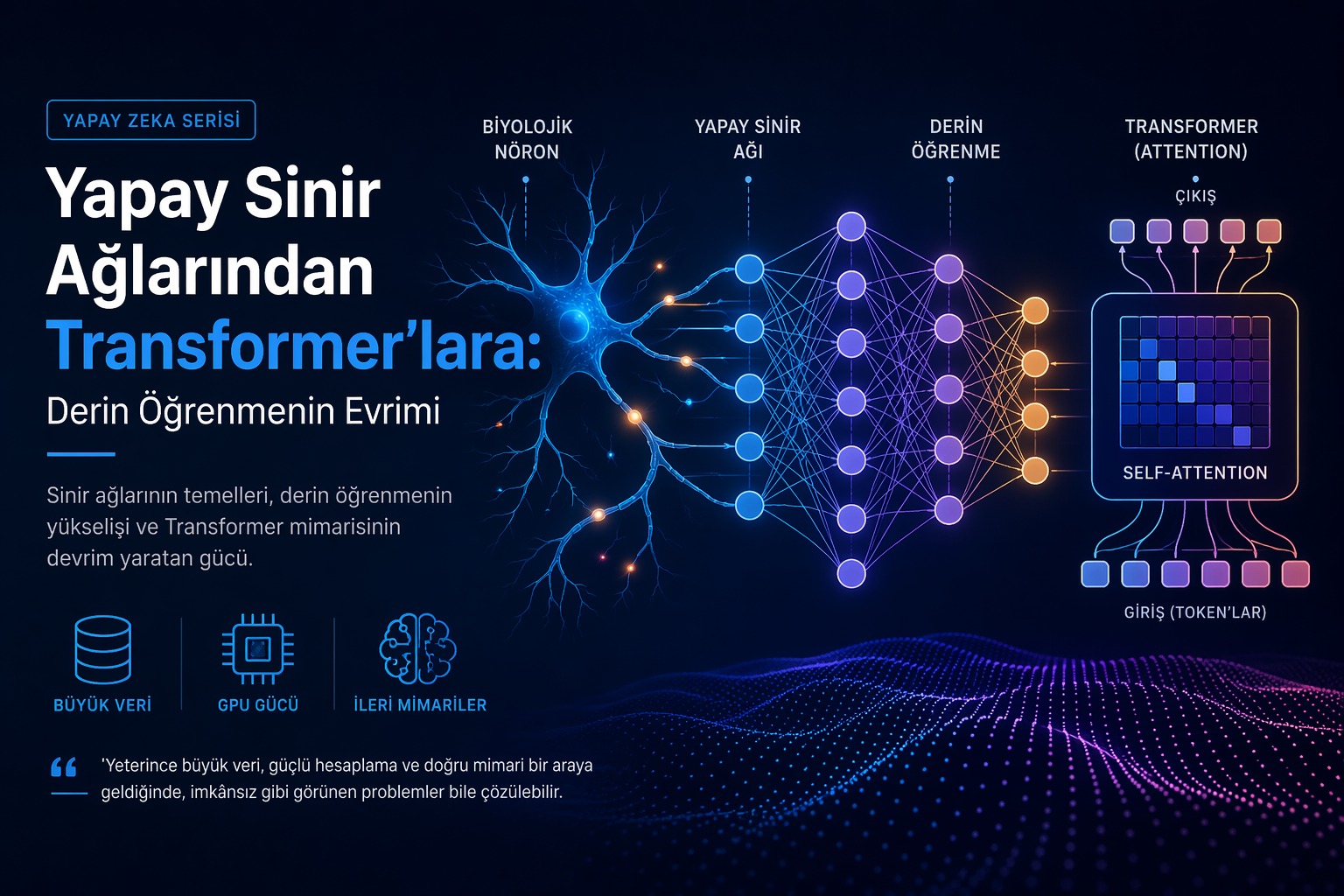
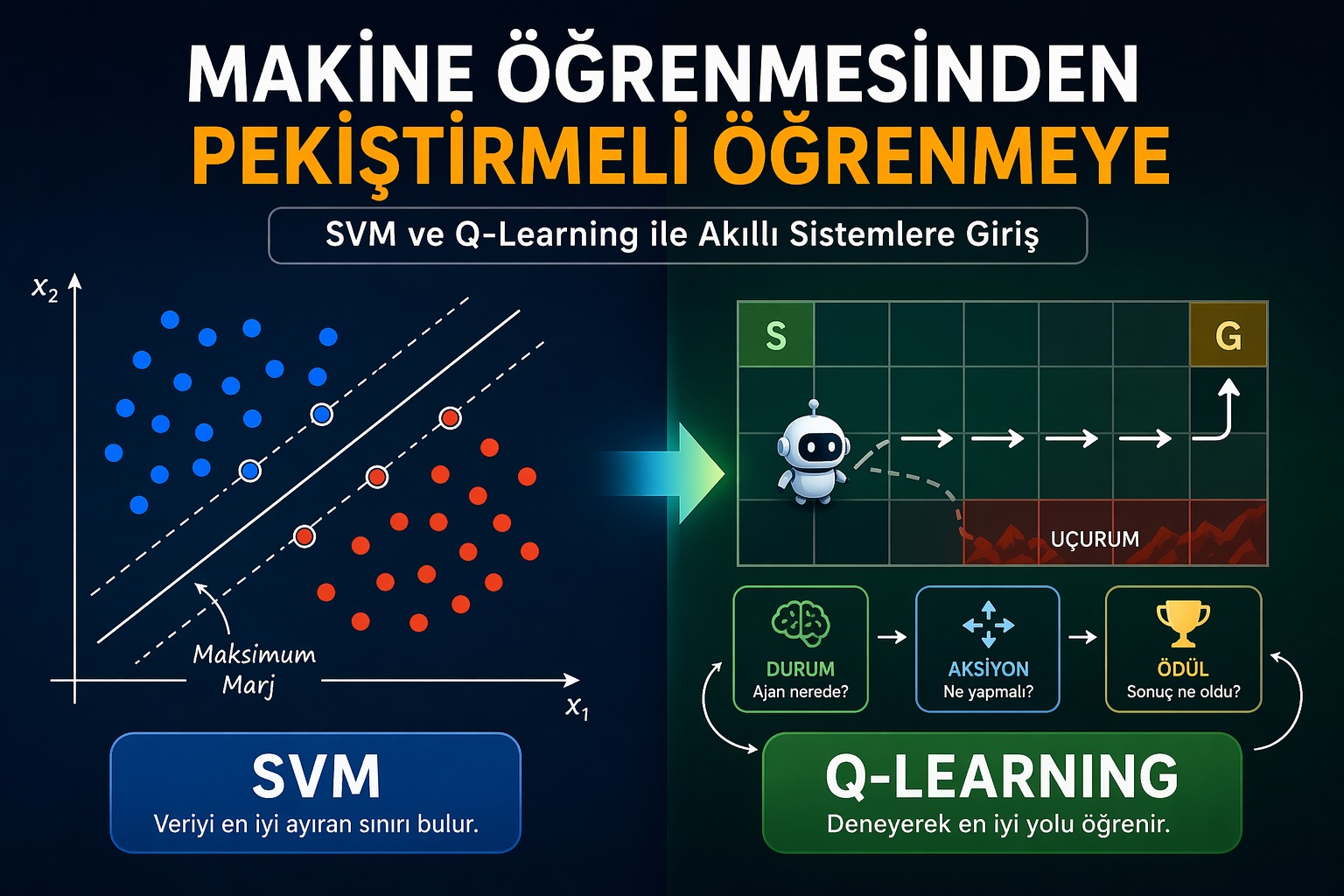
K-Means Algoritması: Verideki Gizli Desenleri Ortaya Çıkaran Güçlü Kümeleme Yöntemi

Veri bilimi projelerinde en zorlayıcı durumlardan biri, elimizdeki verinin etiketsiz olmasıdır. Yani hangi verinin hangi gruba ait olduğunu bilmeyiz. İşte bu noktada devreye gözetimsiz öğrenme (unsupervised learning) teknikleri girer. Bu teknikler arasında hem teorik olarak köklü hem de pratikte son derece yaygın kullanılan yöntemlerden biri K-Means kümeleme algoritmasıdır.
Bu yazıda K-Means’i yalnızca temel mantığıyla değil; matematiksel arka planı, parametre seçimi, gerçek hayat uygulamaları, güçlü ve zayıf yönleriyle kapsamlı şekilde ele alacağız.
K-Means Nedir?
K-Means, veri noktalarını K adet kümeye ayırmayı amaçlayan bir kümeleme algoritmasıdır. Buradaki “K” değeri, veriyi kaç gruba bölmek istediğimizi belirten parametredir.
Algoritmanın optimizasyon hedefi şudur:
Aynı küme içindeki veriler birbirine mümkün olduğunca benzesin, farklı kümeler ise birbirinden olabildiğince ayrı olsun.
Bu hedef matematiksel olarak şu fonksiyonun minimize edilmesiyle ifade edilir:
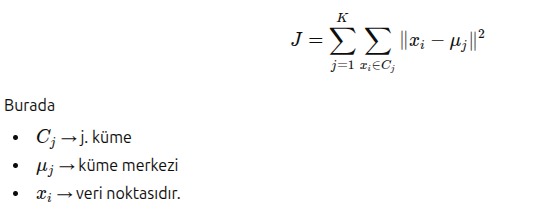
Algoritma Nasıl Çalışır?
K-Means iteratif çalışan bir optimizasyon yöntemidir ve şu adımları izler:
1. K değerini belirleme
Kaç küme oluşturulacağına karar verilir.
2. Başlangıç merkezleri seçimi
Veri içinden rastgele K adet nokta seçilir. Bu noktalara centroid denir.
3. Atama adımı
Her veri noktası kendisine en yakın merkeze atanır. Mesafe ölçümü genellikle Öklid mesafesidir:
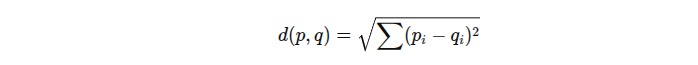
4. Güncelleme adımı
Her kümedeki noktaların ortalaması alınarak yeni merkez hesaplanır.
5. Yakınsama
Merkezler değişmeyene kadar 3 ve 4. adımlar tekrarlanır.
Sezgisel Anlatım
K-Means’i şu benzetmeyle düşünebilirsin:
Masaya saçılmış metal bilyeleri mıknatıslarla toplamak.
Mıknatıslar merkezlerdir. Bilyeler en yakın mıknatısa gider. Mıknatıslar da ortalamaya kayar. Sistem sonunda dengelenir.
Gerçek Hayat Kullanım Alanları
1. Müşteri Segmentasyonu
Perakende şirketleri müşterileri davranışlarına göre gruplar:
-
sadık müşteriler
-
indirim avcıları
-
pasif müşteriler
Her gruba farklı pazarlama stratejisi uygulanır.
2. Görüntü Sıkıştırma
Bir görüntüde milyonlarca renk olabilir. K-Means ile bu renkler sınırlı sayıya indirgenir. Böylece:
-
dosya boyutu küçülür
-
işlem maliyeti azalır
3. Anomali Tespiti
Normal veri kümelenir. Kümelerden uzak kalan noktalar:
→ potansiyel hata
→ dolandırıcılık
→ siber saldırı olabilir.
4. Biyoinformatik
Gen ifade verileri kümelenerek:
-
hastalık alt türleri
-
biyolojik benzerlikler
tespit edilebilir.
Doğru K Değeri Nasıl Seçilir?
En yaygın yöntem Dirsek Yöntemi (Elbow Method)’dir.
Farklı K değerleri için hata (WCSS) hesaplanır ve grafik çizilir. Eğrinin keskin kırıldığı nokta ideal K kabul edilir.
Alternatif metrikler:
-
Silhouette skoru
-
Davies–Bouldin indeksi
-
Gap statistic
Avantajları
-
Büyük veriyle hızlı çalışır
-
Uygulaması kolaydır
-
Paralelleştirilebilir
-
Sonuçları yorumlaması basittir
Dezavantajları
-
Başlangıç merkezlerine duyarlıdır
-
Aykırı değerlere hassastır
-
Küre biçimli kümelerde iyi çalışır
-
K sayısı önceden bilinmelidir
-
Global optimum garantisi yoktur
Gelişmiş Varyantlar
Standart algoritmanın modern veri setlerine uyarlanmış sürümleri vardır:
-
MiniBatch K-Means → büyük veri için hızlı versiyon
-
K-Medoids → ortalama yerine gerçek veri noktası kullanır
-
Fuzzy C-Means → bir nokta birden fazla kümeye ait olabilir
-
Bisecting K-Means → hiyerarşik yaklaşım sunar
Ne Zaman Kullanılmamalı?
K-Means iyi seçim değildir eğer:
-
kümeler farklı yoğunlukta
-
doğrusal olmayan dağılım varsa
-
veri kategorikse
-
kümeler düzensiz şekilliyse
Bu durumlarda DBSCAN veya hiyerarşik kümeleme daha iyi sonuç verebilir.
Sonuç
K-Means, veri biliminin en temel keşif araçlarından biridir. Basit görünmesine rağmen:
-
veri keşfi
-
model ön işleme
-
veri sıkıştırma
-
müşteri analizi
gibi birçok kritik süreçte aktif rol oynar.
Kısaca özetlersek:
K-Means = benzer verileri bir araya getirerek verinin gizli yapısını ortaya çıkaran güçlü bir algoritma.
Kaynaklar
K-Means modern veri biliminin temel algoritmalarından biridir ve literatürde sağlam bir geçmişe sahiptir. Önemli referanslar:
-
J. B. MacQueen (1967) — algoritmanın ilk formülasyonu
-
Stuart Lloyd (1982) — optimizasyon yaklaşımı
-
Trevor Hastie, Robert Tibshirani, Jerome Friedman — The Elements of Statistical Learning, Springer
-
Scikit-learn resmi dokümantasyonu
-
IEEE makale arşivi